
1. 전체 흐름 파악하기

음성 파일이 어디에서 와서 어디로 가는지, Gemini에게 어떻게 옮겨가는지 아는 게 Point!
음성 파일을 n8n으로 전달하면,
Gemini가 음성을 전사하고
AI가 교정·요약 후
Google Drive 저장 및
Notion 회의록을 자동 생성하는
워크플로우
https://github.com/ggplab/n8n-playbook/tree/main/01-hanbit-n8n-guidebook/chap5
1-1. 음성 파일을 n8n으로 전달하면 ( On Form submission )

On Form submission
[Form Elements]
- Label // 이름 설정
- Element Type // 오디오 '파일'이니 'File'로 설정 ⭐
제출 시 Binary 파일이 생성되며 오디오 파일에 대한 정보를 카드로 볼 수 있음
1-2. Gemini가 음성을 전사하고 ( Gemini 의 Transcribe a recording)
Gemini 의 Transcribe a recording 노드 역할 : On Form submission 노드로 받은 음성 파일을 따로 텍스트로 정리
그리고 압정 핀을 사용하여 여러번 실행할 필요 없이 그냥 뒤에 있는 데이터를 고정시킬 수 있다.
1-3. AI가 교정·요약 후 (Gemini의 Message a model ×2)
더보기를 누르면 프롬프트를 볼 수 있다.
| 교정 프롬프트 | 요약 프롬프트 |
| 당신은 전문적인 교정 및 편집 에디터입니다. 아래 제공되는 [음성 인식 텍스트]를 바탕으로 다음의 [작업 지침]을 엄격히 준수하여 텍스트를 다듬어 주세요. [작업 지침] 1. 교정 및 윤문: 맞춤법, 띄어쓰기, 문법 오류를 수정하고 문장의 흐름이 자연스럽게 이어지도록 매끄럽게 다듬으세요. 2. 길이 유지 (요약 금지): 내용을 요약하거나 축약하지 마세요. 원문의 정보량과 길이를 그대로 유지해야 합니다. 3. 누락 방지: 텍스트의 시작부터 끝까지, 어떤 문장도 누락되지 않도록 꼼꼼하게 검토하여 변환하세요. 4. 문맥 수정: 음성 인식(STT) 과정에서 잘못 인식된 것으로 보이는 단어나 문맥상 어색한 표현은 상황에 가장 적합한 단어로 수정하세요. 5. 출력 형식: 교정이 완료된 텍스트만 출력하세요. (인사말이나 부가 설명 생략) |
당신은 비즈니스 문서 정리에 특화된 '수석 서기'입니다. 제공된 회의 스크립트(타임코드 포함)를 분석하여, 다음 JSON 포맷으로 정리된 회의록을 작성하세요. [출력 포맷 - JSON] { "meeting_date": "미팅 날짜 (YYYY-MM-DD 형식. 값이 없는 경우 {{ $now.setZone('Asia/Seoul').toFormat('yyyy-MM-dd') }} 를 기본값으로 설정)", "meeting_title": "회의 주제", "meeting_oneline": "한줄 요약", "meeting_attendee": ["참석자1", "참석자2"], "meeting_summary": "미팅 요약 (아래 작성 지침에 따른 마크다운 형식의 텍스트, 2000자 미만)" } [meeting_summary 작성 지침 - 엄격 준수] 1. 3줄 요약 (Executive Summary) - 회의의 핵심 목적과 결론을 가장 중요한 순서대로 딱 3문장으로 요약하세요. 2. 발언자별 핵심 발언 (Who Said What) - 담당 업무는 제외하고, 각 참여자가 회의에서 논의한 주요 의견만 간결하게 요약하세요. - 형식: **이름**: 주요 발언 요약 3. 담당자별 액션 아이템 (Action Items by Assignee) - 회의에서 도출된 할 일을 담당자별로 그룹화하여 정리하세요. - 공동 작업이거나 담당자가 불명확할 경우 '공통' 또는 '팀 전체'로 분류하세요. - 형식: - **담당자명** - [ ] 할 일 내용 (마감: 문맥상 날짜가 유추될 경우 기입, 아니면 빈칸) - [위험 고지] 액션 아이템의 마감 기한은 문맥상 명확하게 언급되었을 때만 기입하며, 유추된 마감일에는 더블 체크가 필요함을 상기하세요. [주의사항] - 응답은 오직 JSON 데이터만 출력하세요. - meeting_summary 필드에 마크다운 줄바꿈(\n)을 포함하여 텍스트로 넣으세요. |
| 결과 |
| text:{\n "meeting_date": "2026-06-04",\n "meeting_title": "제1차 본회의: 국무총리 및 국무위원 출석 요구의 건",\n "meeting_oneline": "교섭단체 대표연설을 위한 국무총리 및 국무위원 출석 요구안 가결 및 신규 의사봉 도입 보고",\n "meeting_attendee": [\n "우원식(국회의장)",\n "유상범(의원)"\n ],\n "meeting_summary": "### 1. 3줄 요약 (Executive Summary)\n- 제1차 본회의를 개회하여 국정에 관한 교섭단체 대표연설을 위한 국무총리 및 국무위원 출석 요구의 건을 최종 가결하였습니다.\n- 파손된 기존 의사봉과 의사봉판을 역사 기록물로 보존하기로 결정하고, 금일부터 새로운 의사봉 세트를 도입하여 사용하기 시작했습니다.\n- 2월 3일과 4일 양일간 진행될 대표연설에 국무총리를 포함한 전체 국무위원이 출석할 것을 확정했습니다.\n\n### 2. 발언자별 핵심 발언 (Who Said What)\n- **우원식**: 파손된 기존 의사봉을 기록물로 보존하고 새 비품 사용을 안내했으며, 제안된 국무위원 출석 요구안에 대해 이의 없음을 확인하여 가결을 선포함.\n- **유상범**: 헌법 및 국회법에 의거하여 2월 3일~4일 예정된 교섭단체 대표연설을 위해 국무총리 및 모든 국무위원의 본회의 출석을 정식 요청함.\n\n### 3. 담당자별 액션 아이템 (Action Items by Assignee)\n- **우원식**\n - [ ] 파손된 기존 의사봉 및 의사봉판의 전시 방안 검토 (마감: )\n- **공통**\n - [ ] 2월 3일~4일 국정에 관한 교섭단체 대표연설 운영 준비 (마감: 2026-02-03)"\n} |
1-3-1. 추가 설정

1-4. Google Drive 저장 및 (Convert to File)
Convert to File 노드의 역할 : Transcribe a recording 노드로 만든 텍스트를 다시 파일로 만듦.
{{ $('On form submission').item.json.data[0].filename }}_회의록.txt
파일로 만들어야 구글 드라이브에 저장하든 노션에 저장하든 할 수 있는 것일까?
유용한 점은 추가 옵션에서 File Name을 지정할 때, 전전 노드(On form submission)에서의 파일 자체의 이름을 드래그 앤 드롭으로 가져올 수 있다는 점이다. 그래서 이름 주소를 보면, 이 아이템이 json파일의 0번째 데이터의 filename을 가져오는 것을 확인할 수 있다. 음성 파일이 텍스트 파일이 되었다.
그리고 강의에서는 미리 백업하는 용도로 미리 Google Drive에 저장한다. 근데 여기서 기껏 convert to file에 저장해둔 파일 이름을 사용안하길래 나는 임의로 {{ $binary.data.fileName }} 라고 설정했다.
그리고 강의에서 요약하기 전에 Google Drive에 저장을 하는데, 약간 백업 용도로 생각하며 좋을 것 같다.
1-5. Notion 회의록을 자동 생성하는 워크플로우 (Notion)



삼점바 -> 연결 -> 연결 개발 또는 관리 선택 -> 신규 연결


좌측 연결 페이지 선택 -> 토큰 복사 및 노드에 붙여넣기
2. 결과 및 느낀 점
AI 교정, 요약 프롬프트 중 Json 포맷이 가장 중요한 것 같다. 음성 파일의 내용을 잘 나눠야 노션에 적절하게 배분할 수 있기 때문이다.

[기본 미션] ✅
CHAPTER 05 회의록 STT 워크플로우(오디오 파일 → Gemini STT → 교정 → 요약 → Google Drive + Notion 업로드)를 따라 워크플로우를 직접 만들고, 예제 오디오 파일(chap5_STT_example_audio.mp3)로 실행해 생성된 Notion 회의록 페이지와 Google Drive 전사 파일 링크를 블로그에 정리해 보세요.
※ iOS 사용자는 단축어, Android 사용자는 Google Drive 트리거 또는 Telegram 봇 중 편한 방식을 선택해 주세요.
[심화 미션]
본인의 실제 업무 또는 관심 분야에 맞게 음성 입력과 요약 포맷을 커스텀해 보세요.
- 트리거를 변경: 실제로 녹음한 회의/강의/인터뷰 음성을 입력✅
- 요약 프롬프트를 본인 업무 포맷에 맞게 재작성 (예: 영업 미팅 → 고객·니즈·다음 액션 / 강의 → 핵심 개념·예시·숙제)✅
- 출력 저장소 변경: Notion 대신 Obsidian, Google Docs, 사내 위키 등
- 한 발 더: 요약 결과에서 '액션 아이템'만 뽑아 별도 Task 관리 도구(Todoist, ClickUp 등)에 자동으로 쌓이도록 확장
기본 미션 결과


집중이 안되는 강의를 스크립트와 함께 봤을 때, 집중력이 올라간다는 것을 확인할 수 있었다. 그럼 내가 듣는 강의를 모두 텍스트 파일로 만들어서 분석하는 건 효율적일까? 굳이 다른 툴로 편하게 하고 있는데 이 방법을 이용할 필요는 없을 것 같다는 생각이 들었다. 어차피 할거면 매일 하는 걸 정리하는 게 좋지 않을까? 그럼 영어를 매일 하고 있으니 이걸 정리하는 편이 좋을 것 같다.
심화 미션 결과 (막힌 점 : 어떤 처리 결과를 내놓아 활용할지 고민 중)
여러 개의 오디오 파일을 받았을 때, 처리하도록 code 노드를 사용하였다.
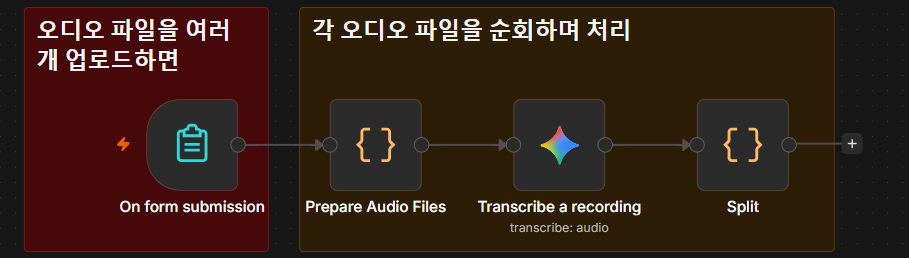
더보기를 누르면 코드를 볼 수 있다.
Prepare Audio Files
// 1. 데이터 가져오기
const inputData = $input.first();
const files = inputData.json.data;
const binaryData = inputData.binary;
if (!files || !Array.isArray(files)) {
return [];
}
// 2. 파일 정보에 원래 n8n 매핑 인덱스(원래 위치)를 기록해 둡니다.
const filesWithIndex = files.map((file, index) => ({
...file,
originalIndex: index
}));
// 3. 파일 이름(filename)을 기준(01, 02, 03...)으로 정렬합니다.
filesWithIndex.sort((a, b) => {
return a.filename.localeCompare(b.filename, undefined, { numeric: true, sensitivity: 'base' });
});
// 4. 정렬된 순서대로 JSON과 실제 오디오 바이너리를 매핑하여 내보냅니다.
const result = [];
filesWithIndex.forEach((file, sortedIndex) => {
const binaryKey = `data_${file.originalIndex}`; // 원래 바이너리 키 찾기
const newItem = {
json: {
// ⭐ [변경/추가] 명확한 구분을 위한 인덱스와 파일명 최상위 배치
itemIndex: sortedIndex + 1, // 1부터 시작하는 순번 (1, 2, 3...)
displayTitle: `[파일 ${sortedIndex + 1}] ${file.filename}`, // 디스플레이용 이름
fileName: file.filename,
mimeType: file.mimetype,
fileSize: file.size,
submittedAt: inputData.json.submittedAt
}
};
// 실제 오디오 파일 데이터가 존재하면 바이너리 필드도 함께 넘겨줍니다.
if (binaryData && binaryData[binaryKey]) {
newItem.binary = {
data: binaryData[binaryKey] // Gemini 노드가 읽을 'data' 필드로 통일
};
}
result.push(newItem);
});
return result;
Split
// Transcribe a recording 노드에서 넘어온 모든 아이템을 순회합니다.
return $input.all().map((item, index) => {
// 1. Gemini 오디오 인식 결과에서 원문 텍스트 추출
let fullText = "";
if (item.json.content && item.json.content.parts && item.json.content.parts[0]) {
fullText = item.json.content.parts[0].text || "";
}
let essayPart = fullText;
let dialoguePart = "";
// 2. 앞에 \n이나 공백이 붙어있어도 칼같이 식별하는 정규식
const dialogueRegex = /\s*Dialogue\s+[Pp]ractice/;
const match = fullText.match(dialogueRegex);
if (match) {
const dialogueIndex = match.index;
// 키워드 앞부분(에세이) 자르고 깔끔하게 여백 정리
essayPart = fullText.substring(0, dialogueIndex).trim();
// 키워드부터 끝까지(대화문) 자르고 깔끔하게 여백 정리
dialoguePart = fullText.substring(dialogueIndex).trim();
}
// ⭐ 3. 글자 형태의 '\\n'과 실제 엔터값('\n')을 모두 제거하고 한 칸 공백(' ')으로 치환
// 연속된 공백이 생기지 않도록 깔끔하게 정돈합니다.
essayPart = essayPart
.replace(/\\n/g, ' ') // 글자 모양 '\n' 제거
.replace(/\n/g, ' ') // 실제 줄바꿈 엔터 제거
.replace(/\s+/g, ' ') // 줄바꿈이 지워지면서 생긴 중복 공백들을 한 칸 띄어쓰기로 통일
.trim();
dialoguePart = dialoguePart
.replace(/\\n/g, ' ') // 글자 모양 '\n' 제거
.replace(/\n/g, ' ') // 실제 줄바꿈 엔터 제거
.replace(/\s+/g, ' ') // 중복 공백 통일
.trim();
// 4. 역사 속으로 사라진 파일명을 'Prepare Audio Files' 노드에서 강제로 추적해 오기
let originalFileName = "";
let itemIdx = index + 1; // 기본 순번
try {
const sourceNode = $("Prepare Audio Files");
if (sourceNode && sourceNode.all && typeof sourceNode.all === 'function') {
const allSourceItems = sourceNode.all();
if (allSourceItems[index] && allSourceItems[index].json) {
originalFileName = allSourceItems[index].json.fileName || "";
itemIdx = allSourceItems[index].json.itemIndex || itemIdx;
}
}
} catch (e) {
try {
const prevData = $item(index).node('Prepare Audio Files').json;
originalFileName = prevData.fileName || "";
itemIdx = prevData.itemIndex || itemIdx;
} catch (err) {
originalFileName = `입트영_오디오_파일_${itemIdx}.mp3`;
}
}
// 5. 정돈된 최종 알맹이 데이터만 반환
return {
json: {
itemIndex: itemIdx, // 1, 2, 3... 순번 확보
fileName: originalFileName, // 깨지지 않는 원래 파일 이름 확보
essay: essayPart, // 모든 줄바꿈이 제거된 매끄러운 통문장 에세이
dialogue: dialoguePart // 모든 줄바꿈이 제거된 매끄러운 통문장 대화문
}
};
});
사실 뒤에 어떤 AI를 붙여야 잘 사용할 수 있을지 고민 중이다. 공부를 하면서 덧붙여봐야겠다.